Baram Seminar DeepLearning Day2
오늘도 광운대학교 로봇학부 동아리인 바람에서 진행하는 딥러닝 세미나에 참석했습니다.
오늘은 딥러닝 세미나 2일차입니다.
딥러닝에 대하여 자세한 내용을 배울 것 같아 기대됩니다.
지금부터, 딥러닝 세미나 2일차에 참여하여 배우고 생각한 내용들을 정리하여 기록해 보겠습니다.
인공지능 학습의 종류
인공지능의 학습은 아래와 같이 종류가 있으며, 설명할 수 있겠습니다.
- 지도학습
응애 나 애기, 뭐가 뭔지 다 알려줘!
- 비지도학습
내가 특징을 파악해볼게~
- 자기지도학습
반핑프
- 강화학습
잘하면 당근, 못하면 채찍
1. 지도학습
지도학습은 정답을 알고 있습니다. (= 주입식교육)
지도학습은 회귀(regression)와 분류(classification)으로 나뉩니다.
2. 비지도학습
비지도학습은 정답(label)을 모릅니다.
비지도학습은 군집화(clustering)와 차원축소로 나뉩니다.
- 군집화 : k-means, DBSCAN 등..
- 차원축소 : PCA, SVD 등..
3. 자기지도학습
풀어야 하는 문제 외에 다른 문제(pretext test)를 새로 정의해서 먼저 풀어보는 학습 방식입니다.
즉, 자기지도학습은 데이터 내에서 스스로 정답(label)을 만듭니다.(pretext test에 대한 정답)
자기주도학습은 전이학습의 선행 과정이라고 할 수 있습니다.
4. 강화학습
동물의 학습 능력을 모방한 것입니다.
특정 상태(state)에서 어떤 행동(action)이냐에 따라 보상(reward)이 나뉩니다.
- 잘 수행할 경우 : 보상 있음.
- 잘 수행하지 못할 경우 : 보상 없음.
Hyper Parameter
Hyper Parameter는 직접 지정해 주어야 하는 데이터입니다.
- 총 Epoch 수 : 전체 데이터를 몇 번 반복해서 볼 것 인지 나타내는 용어입니다.
- Batch Size : 한 번 볼 때, 몇 개씩 볼 것인지 나타내는 용어입니다.
- Learning Rate(학습률) : 얼마나 갈 것인지(학습할 것인지)를 나타내는 용어입니다.
Loss Function
Loss Function = Guide Line
우리가 만든 모델이 얼마나 ‘잘’ 혹은 ‘못’하고 있는지 알려주는 지표입니다.
어떻게 알려줄까?
=> 수학 공식을 이용하여 알려줍니다.
Global Minimum
손실이 최소가 되는 지점입니다. Loss가 최소화되는 지점으로 학습되면, 좋은 모델이라고 말할 수 있습니다.
최적의 W(가중치)와 b(편향)을 찾는 것이 중요합니다. 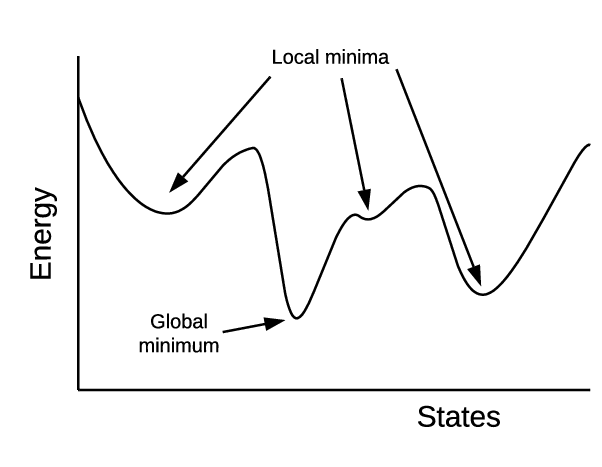 자료 출처 : 원본 자료 출처 확인 안 됨.
자료 출처 : 원본 자료 출처 확인 안 됨.
Optimizer
Optimizer(최적화 알고리즘) : Loss Function의 최솟 값을 구하는 데 도움을 줍니다.
Gradient Descent(GD)
Gradient Descent(GD)는 ‘경사 하강법’으로 불립니다. 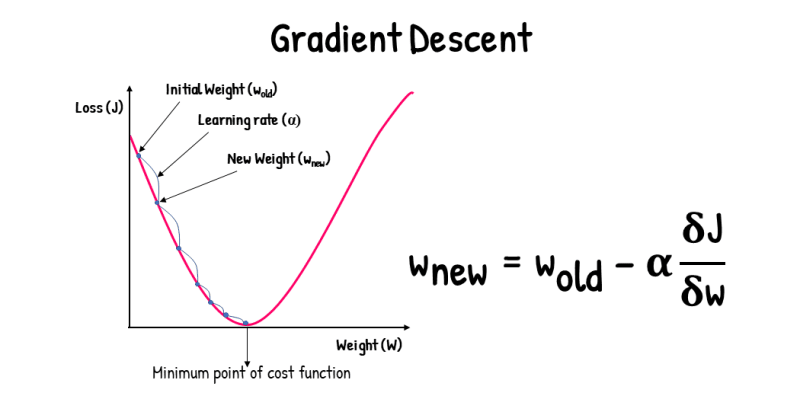 자료 출처 : 원본 자료 출처 확인 안 됨.
자료 출처 : 원본 자료 출처 확인 안 됨.
학습률(a)이 너무 높으면 Minimum Point를 건너뛸 수 있음.
Stochastic Gradient Descent
Stochastic Gradient Descent(SGD)는 ‘확률적 경사 하강법’으로 불립니다.
마무리
오늘은 이렇게 바람에서 진행된 딥러닝 세미나 2일차에 참석하여 인공지능에 대하여 배울 수 있었습니다.
개념 위주의 세미나이기에 인공지능에 대하여 거부감 없이 친숙하게 배울 수 있었던 것 같습니다.
고등학생 때 배웠던 내용이지만, 까먹어서 기억이 잘 나지 않았습니다.
그래도, 강의를 진행해주신 선배님께서 친절히 설명해 주셨기에 다시 떠올리며 복습할 수 있게 되었습니다.
세미나 녹화 영상 : 바람 공식 유튜브 - [파이썬 없이 배우는 딥러닝] OT & 인공지능의 기초 : 머신러닝과 딥러닝의 이해